
在 SQL Server 中,PARTITION BY 是用于在窗口函数(如 ROW_NUMBER(), RANK(), DENSE_RANK(), SUM(), AVG(), 等等)中定义分区的一种方法。分区允许你在查询结果集的特定子集中应用窗口函数,而不是在整个结果集上应用。
使用场景
1.排名:如上面的例子,可以使用 ROW_NUMBER(), RANK(), 或 DENSE_RANK() 来计算分区内的排名。
2.累积和/移动平均:可以使用 SUM(), AVG() 等聚合函数来计算分区内的累积和或移动平均。
3.分组计算:可以在每个分区内执行特定的计算,而不需要使用子查询或 GROUP BY。
举个例子,我们先准备好一个学生成绩表的数据源
create table Student --学生成绩表
(
id int, --主键
Grade int, --班级
Score int --分数
);
insert into Student values(1,1,88);
insert into Student values(2,1,66);
insert into Student values(3,1,75);
insert into Student values(4,2,30);
insert into Student values(5,2,70);
insert into Student values(6,2,80);
insert into Student values(7,2,60);
insert into Student values(8,3,90);
insert into Student values(9,3,70);
insert into Student values(10,3,80);
insert into Student values(11,3,80)一:如果我们想要一个输出每个学生成绩名次的结果,就可以使用row_number() 方法,配合排序
select *,row_number() over(order by Score desc) as Sequence from Student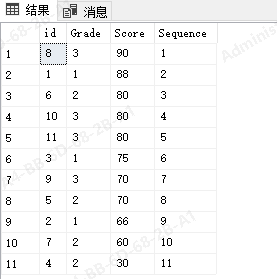
二:如果我们想要对每个年级的学生的名词分别计算,那就要使用到partition by方法
select *,row_number() over(partition by Grade order by Score desc) as Sequence from Student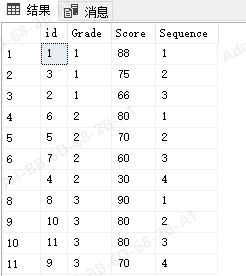
接下来,我们还可以利用上述结果进行二次筛选,比如获取每个年级第一名
select * from (
select *,row_number() over(partition by Grade order by Score desc) as Sequence from Student
) T
where T.Sequence<=1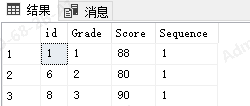
在这里,我们发现一个现象,当存在一个分数一样的情况,比如三年级有2个80分,但是他们的排名却分了前后,如果要想排名一致,都是第二名,就可以使用rank()方法
三:按照年级,输出每个学生的排名,同分数排名一致
select *,rank() over(partition by Grade order by Score desc) as Sequence from Student;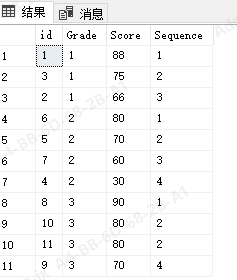
此时,我们再获取每个年级前2名,就可以取出分数并列第二名的同学
select * from (
select *,rank() over(partition by Grade order by Score desc) as Sequence from Student
) T
where T.Sequence<=2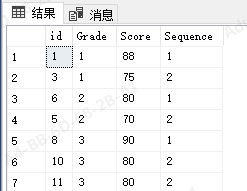
注意事项
PARTITION BY 子句中的列应仔细选择,因为它们会影响查询的性能。
如果不需要分区,可以省略 PARTITION BY 子句,此时窗口函数将在整个结果集上应用。
可以结合多个列进行分区,例如 PARTITION BY Grade。
通过使用 PARTITION BY,你可以更灵活和高效地进行数据分析和处理,尤其是在处理大型数据集时。